在这一部分,我们来一起实践一个比较复杂的基于Rasa 3.2.1版本的机器人。代码见此处,查天气功能借鉴了这里的代码,表示感谢!
基本环境
python 3.8.12 rasa_sdk 3.2.2, 推荐使用Conda创建虚拟环境, 玩坏了也不怕。
Rasa初始化
切换到要创建Bot的文件夹,在对应Conda环境cmd输入rasa init即可创建,无需训练,建好的bot如下图所示:
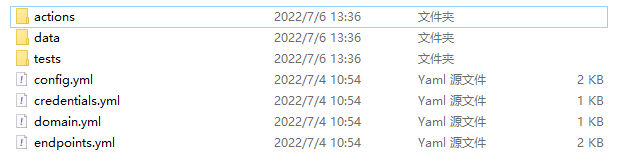
其中actions文件夹配置需要的第三方action功能,在这里我们会写歌曲搜索的一系列action;data文件夹提供nlu.yml、rules.yml、stories.yml;tests文件夹相对不重要,接下来将会从config开始一步步配置。
Rasa Config配置
打开config.yml,可以看到,有如下几个重点配置项:recipe,language,pipeline,policies。
其中:
- recipe的设计是与不同的组件和策略挂钩的,目前保持default.v1不动就可以了;
- language为这个bot设定主要语言,以两字表示,参照Spacy的语言表述形式,我们将en改为zh,即可改为中文;
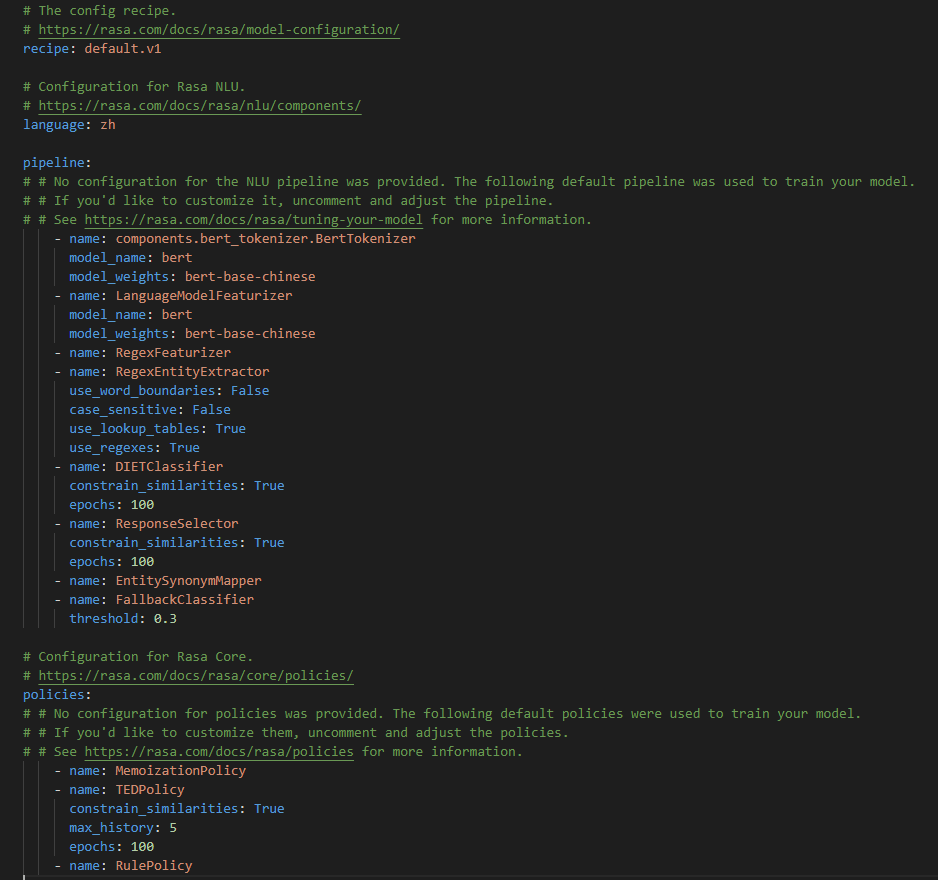
- pipeline配置执行NLU的组件,必选:分词器、特征抽取器、分类器,可选:实体同义词映射、回复选择器、兜底分类器。由于这次要玩的花一点,所以:
- 特征抽取器选择LanguageModelFeaturizer,model_name选择bert,model_weights选择bert-base-chinese即可,这样系统会自动从huggingface的transformers库拖权重下来,如果有本地缓存也可以将model_weights设置为本地缓存路径;
- 分类器选用DIETClassifier;
- 虽然在Rasa的LMFeatureizer中,会对文本自动进行tokenizer,但是如果不配置tokenizer,系统会报错,NLU会把分词后的token放入返回的text_tokens中,所以还是需要一个分词器,可以使用jiebaTokenizer,因为切分结果对LanguageModelFeaturizer并不影响,觉得不合适的话也可以把transformers的tokenizer拆出来作为单独的部分,下面的实践是将tokenizer拆出来单独使用的;
- 兜底分类器选择threshold为0.3的FallbackClassifier,需要在rules中为nlu_fallback设置规则;
- 回复选择器设置100epoch的ResponseSelector;
- 添加EntitySynonymMapper,用于nlu的synonym处理;
- 添加RegexFeaturizer和RegexEntityExtractor用于nlu的lookup处理,需要注意,处理中文需要将RegexEntityExtractor的use_word_boundaries置为false;
- 至于其他featurizer,也可以添加作为sparse特征使用,这里就不添加了。
- policies不用多说,我全都要。
因此,修改后的配置图为:
Rasa domain配置
domain.yml里面配置了大量的有价值信息,默认配置有intents、responses、session_config,显然不太够用,为了添加一些实体信息,我们还会引入entities、slots、forms和自定义的actions来完善domain的配置。
- intents:这里定义了可能需要解析的用户需求,如果用户需求用到了对应的实体,需要标注use_entities并在下面列出对应的实体名称:

- responses:这里定义了各种系统回复及其对应的回复内容:

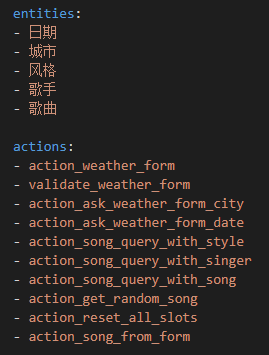
- entities:这里列举可能出现的实体名字;
- actions:这里列举自定义的各类action:
- forms:这里定义了需要完成填充的表格,表格内包含各类槽位,每个槽位都对应着实体,同时需要注意一点,rasa不会自动清除词槽,所以如果需要提交完表单后重置词槽,可以参考代码里的action_reset_all_slots,同时在rules配置即可:
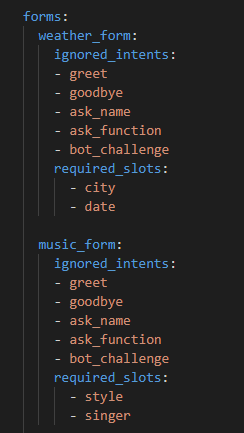
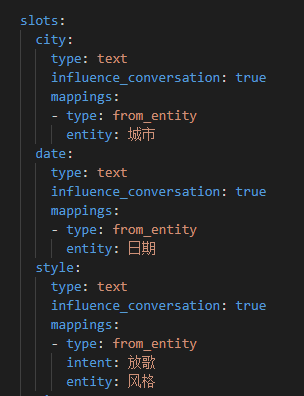
- slots:这里定义了在表格中对应的槽位,以及每个槽位的属性,来源,实体等,注意,如果制定了intent,那么该槽位只接受来自于对应intent的实体,其他的intent就算识别出来实体也不会填充:
- session_config: 定义了本次对话的过期时间,槽位继承相关,这里不做更改。
Rasa NLU配置
data文件夹下的nlu.yml最最最主要的功能是负责意图识别,所以里面包含的nlu,lookup,和synonym都是为意图识别服务的。
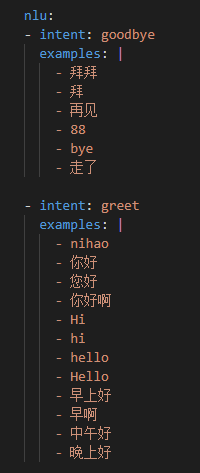
- nlu:nlu部分定义的就是意图,以及意图的表达形式,越全面越好:
- lookup:简言之这个就是一个查表功能,要结合config.yml的RegexFeaturizer和RegexEntityExtractor使用来提取实体:

- synonym:这里专门配置同义词,也就是一个实体不同的说法,需要结合config.yml的EntitySynonymMapper使用,会将所有的表述统一改为指定的词:

Rasa Rules和Stories配置
rule和story有许多区别和坑,简单的概括一下:
- rule定义结束的action一定是后面会跟action_listen,所以配置了rule的intent-action对,在story里面不可以继续跟action,也就是不可以写intent-action-action,而没有在rule内配置的intent-action可以这么写;
- rule的命中评级高于story,有冲突的情况下优先执行rule;
- story是让TED Policy启发式学习的,因为流程多样,所以写法多样,但是最终学到的效果可能一般,比如,story里面定义了“姓名-性别-查天气”的问法,TED也学得很好,F1=1的评分,但是在执行中,用户问了“功能-查天气”,没有命中Rule,TED在预测的时候可能就懵了,默认给了action_listen,导致用户体验不好;
- 官方推荐少写rule多写story。
至于rule的写法,在不涉及到表格填充的时候很简单,就是:
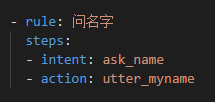
intent-action对,可以无限制写下去。但是一旦涉及到form的填充,问题就来了:

可以看到,复杂程度大幅提高,以询问天气情况意图为例,在接受到这个意图之后,需要进行城市(city)和时间(date)的槽位填充,而这个槽位是定义在weather_form的,所以需要先激活weather_form的action,根据实体识别的结果填充对应槽位,当槽位填充完成之后,会进入active_loop,active_loop表示,表格内槽位完全填充完成之前,会一直停留在表格填充过程;而下面的condition表明,只要处在weather_form的填充中,就会一直关注,到什么时候为止呢,也就是表格填充完成-> active_loop为null时,才会执行下一个action,也就是action_weather_form。
至于story的写法,更加多样化,只需要注意和rule的冲突就可以了:

Rasa 其他配置
credentials.yml:配置各种提供服务的途径,如rest api,socketio, Rasa X, facebook等等,这里不需要动;
endpoints.yml:配置各种外接功能性url,如tracker_store等,在这里配置action server可能会用到action_endpoint的url来寻找action server;
tests文件夹:不管。
项目功能简介
查天气:通过和风天气api,传入时间地点获得天气信息;
查歌曲:使用这里给出的网易云数据集,获取前200歌单信息,导入neo4j进行查询。