上一部分我们了解了Rasa对话机器人的大致框架,文件结构,以及数据流程,这次我们来学习Rasa的一个核心模块:NLU模块,它所负责的是将用户输入的文本进行拆解分词、实体抽取,并将这些识别的结果转为文本特征,送入意图识别器,得到用户输入文本的意图,并将该意图反馈给Rasa Core模块,同时也负责选择机器人对于用户问题的最优回复。
在学习NLU模块之前,有一个小小的问题需要澄清一下,在Rasa 2.x版本中,一切流程都是以pipeline流水线模式执行,,但是Rasa 3.x版本对于结构进行了较大的调整,以图结构代替了传统的流水线结构,使得结构更加灵活,所以接下来将会对各个部分进行介绍。
NLU框架
Rasa3.2.x 的NLU的源码结构图如下图所示:
可以看出,NLU模块提供的主要功能有:
- 分词(tokenizers):Rasa官方支持的分词器有WhitespaceTokenizer(只支持英文,空格分词)、JiebaTokenizer(支持中文,结巴分词)、MitieTokenizer(基于C++开发,中文需要训练)、SpacyTokenizer(基于Cython的高速NLP库,支持中文模型),除此之外,也可以自定义分词器,在最后一部分的实践过程中将会实现基于Bert tokenizer的中文分词方法;
- 文本特征化(featurizers):在特征化部分,Rasa给出了两类特征,一类是稀疏特征,一类是稠密特征。稀疏特征一般是基于统计的ngram特征、count_vectors特征(基于 scikit-learn)等,可能含有大量的0在其中,稠密特征是语言模型直接输出的文本特征,官方支持的语言模型有前面提到的Mitie、Spacy,还有基于transformers的一系列语言模型,如Bert等;
- 意图识别(classifiers):将用户输入的信息归类到之前在domain.yml中列出的意图,以便机器人进行后续处理。有人可能会问,如果用户提问的不在之前所列的意图之中会怎么办,这里我们可以配置一个置信区间,当所有意图的置信度均达不到阈值,会有一个兜底策略(Fallback)回复用户,这个方法我们也会在最后部分的实践过程中给出展示。官方支持的分类器有Mitie、基于scikit-learn的逻辑回归、关键词分类器、自主研发可同时提取实体和做分类的DIET分类器以及用于兜底策略的兜底分类器;
- 实体抽取(extractors):抽取用户输入信息中所具有的人名地名等实体,以供意图识别使用。官方支持的有Mitie、Spacy、CRF、Duckling、正则以及上面提到过的DIET分类器。附加:EntitySynonymMapper(实体同义词映射),这个模块会根据之前定义的同义词自动将识别的实体修正为同一个词汇,简化复杂度;
- 回复选择(selectors):回复选择器的结构和前面提到的DIET结构一致,但它的目的则是检索意图对应的答案,选择给用户最合适的回复。
我们可以看出,上述几个功能中,使用最频繁的可以说是DIET这个模型了,接下来将会对这个模型进行解释,至于其他的NLP处理工具如Mitie、Spacy,感兴趣的可以去对应官网查阅相关资料。下面,开始介绍DIET。
DIET介绍
DIET,全名为Dual Intent and Entity Transformer,是Rasa团队提出的可以用于意图分类和实体识别的多任务框架,它可以在仅使用词和字符级ngram的稀疏特征情况下,取得较高的准确性,当然也可以结合预训练模型的embedding来进一步提升任务的准确性,由于不需要pretrained embedding,减少了大量参数,所以模型的训练速度也大大提高,在CPU也可以轻松的完成训练。
DIET的论文中给出了整个模型的架构,如下图所示:
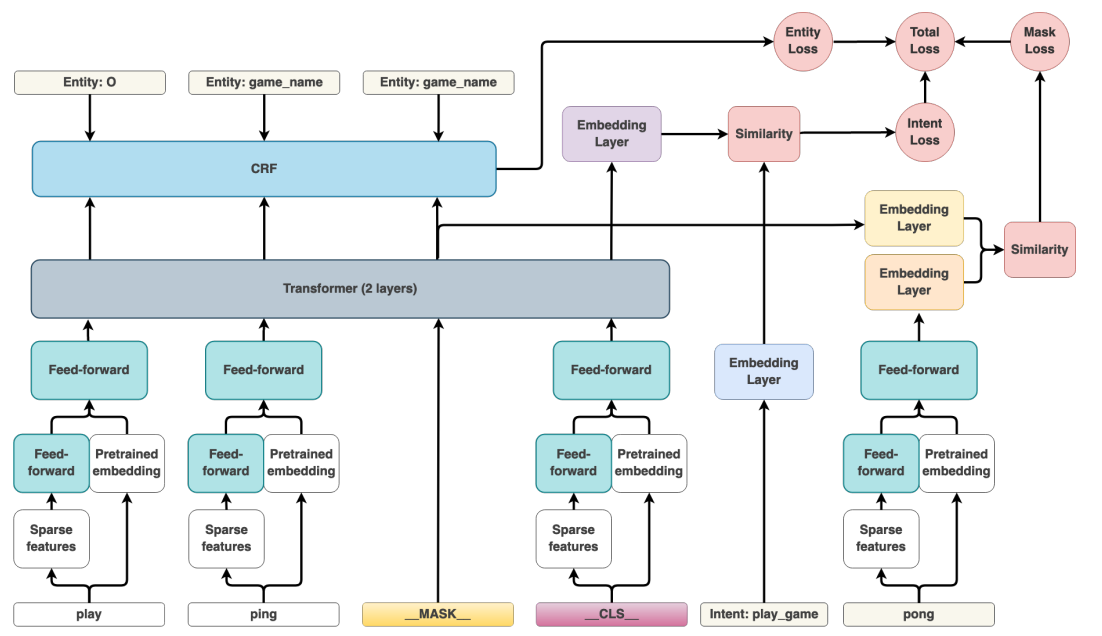
模型看上去并不复杂,从Loss角度看,可以看到这个图里面包含了三类任务:Mask词预测(Mask Loss)、意图识别(Intent Loss)、实体识别(Entity Loss)。其中Mask任务受启发于Pretrained LM训练过程,其Mask算法也与Pretrained LM一致,这项任务可以帮助模型从文本中学习到更多一般的特征,而其他两项任务则是和下游任务相关的。另外需要注意的一点,这三个任务是可以自由配置的,如果只希望模型做分类任务,那么完全可以关闭Mask任务和意图识别,以加速训练。
接下来,我们从下往上一层层看。首先,输入的每个token可以有其sparse特征或dense特征(经过Pretrained embedding),为了融合sparse特征,会有一层前馈神经网络将稀疏特征转为稠密特征,经过一层concat之后就可以将融合的特征送入Feed-forward层,这里有一个很有意思的trick,为了提高模型训练效率,Feed-forward层使用的Dense层并非传统意义的全连接,而是设置了高达80%dropout的RandomlyConnectedDense;同时,在特征输入到Transformer之间的所有FF层,其权重都是共享的,从而进一步加快了模型训练速度。
随后,融合特征被送入Transformer层进行编码,这里可以自由指定所需的transformer层数,Transformer结构和传统transformer结构一致,只是其中的Dense层全部被替换为RandomlyConnectedDense层。
最后,如果做NER任务,那么编码后的特征会被送入CRF层进行实体识别,而cls向量会被用去做意图识别,若做Mask任务,则Mask的embedding会被拿来做token的embedding相似度匹配。
总结
到这里为止,Rasa的NLU模块的大致框架就介绍完毕了,我们来总结一下,这个模块的主要功能在于对用户信息的NLU处理,得到意图送入Rasa Core,算法重点则在于DIET模型的理解,至于转换格式的Emulator、和将模型存储的persistor,相对来说不重要,就不需要额外解释了,下一步我们将一起学习Rasa Core在接收到NLU处理的内容后,对内容进行处理的过程。