在前面几节我们一起学习了Rasa的基本框架,对于Rasa机器人的组成部分、工作流程还有部分模块的工作原理有了一定的了解,接下来会对一些细节做补充,并介绍3.x版本的优化点。
部分细节
- Rasa源码的Telmetry是做什么的?Telemetry是Rasa用来匿名收集语言、策略、pipeline等数据,用来改善Rasa系统的信息收集系统,可以通过rasa telemetry disable停止其功能。
- Rasa的Event Brokers是干啥用的?Event Broker主要用来跨域发布事件,比如将触发的event发送到其他服务进行消息通知或处理对应事件。
- 如何将Rasa引入自己的网站/如何在本机debug Rasa?Rasa提供了多样的channel,通过其提供的restful api或者Websocket可以很方便的将对话功能引入你的网站;本机调试简言之,python切换到bot文件夹,sys argv添加shell,执行rasa main即可。
- Rasa是否包含ASR与TTS?可惜并没有。
- Rasa Form的作用?如何填充?众所周知,在客服类型机器人中常常避免不了的一件事就是填表,无论是买票,订餐,还是售后,都需要有大量的待填充内容,以订机票为例,需要知道出发地、到达地、出发日期时间等等,这些信息在Rasa中会被组合成一个Form,而出发地之类的待填充内容则是From中的槽位(slot),前面我们提到的NLU里面的NER部分,在充分训练后,就可以自动在对话中提取所需的槽位并自动填充,而Policy预测Action会进入Form填充状态(active_loop),引导客户填充slot,直到所有slot填充完成或者被中断才会结束这个过程。
- 一般聊天机器人包含NLU和DM,Rasa的DM在哪里?DM一般来说指的是对话管理部分,也有狭义的认为是对话策略管理,从广义角度看来,整个Rasa Core模组就是DM,根据NLU的输入来决定下一步对话流程,单纯的对话策略管理模块(Policy)也是包含在Rasa Core的一部分。
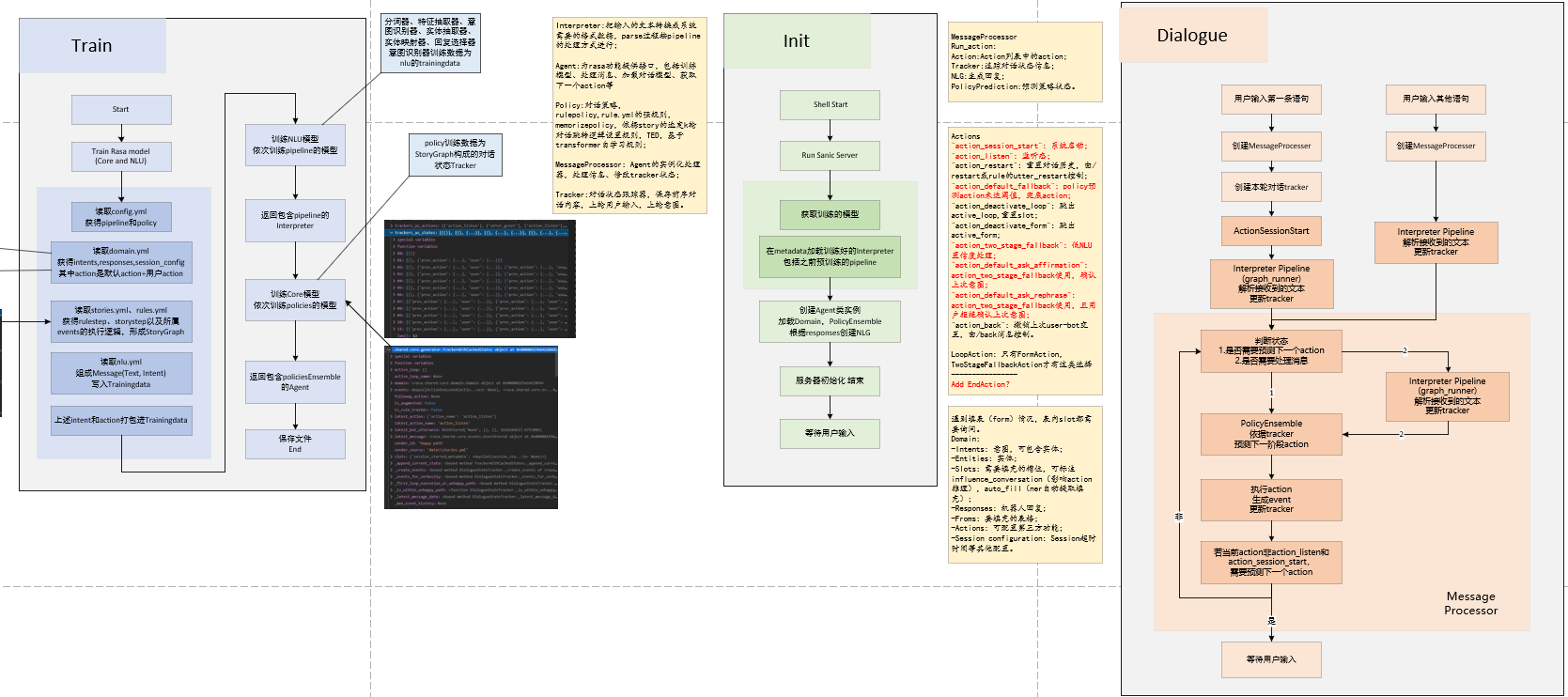
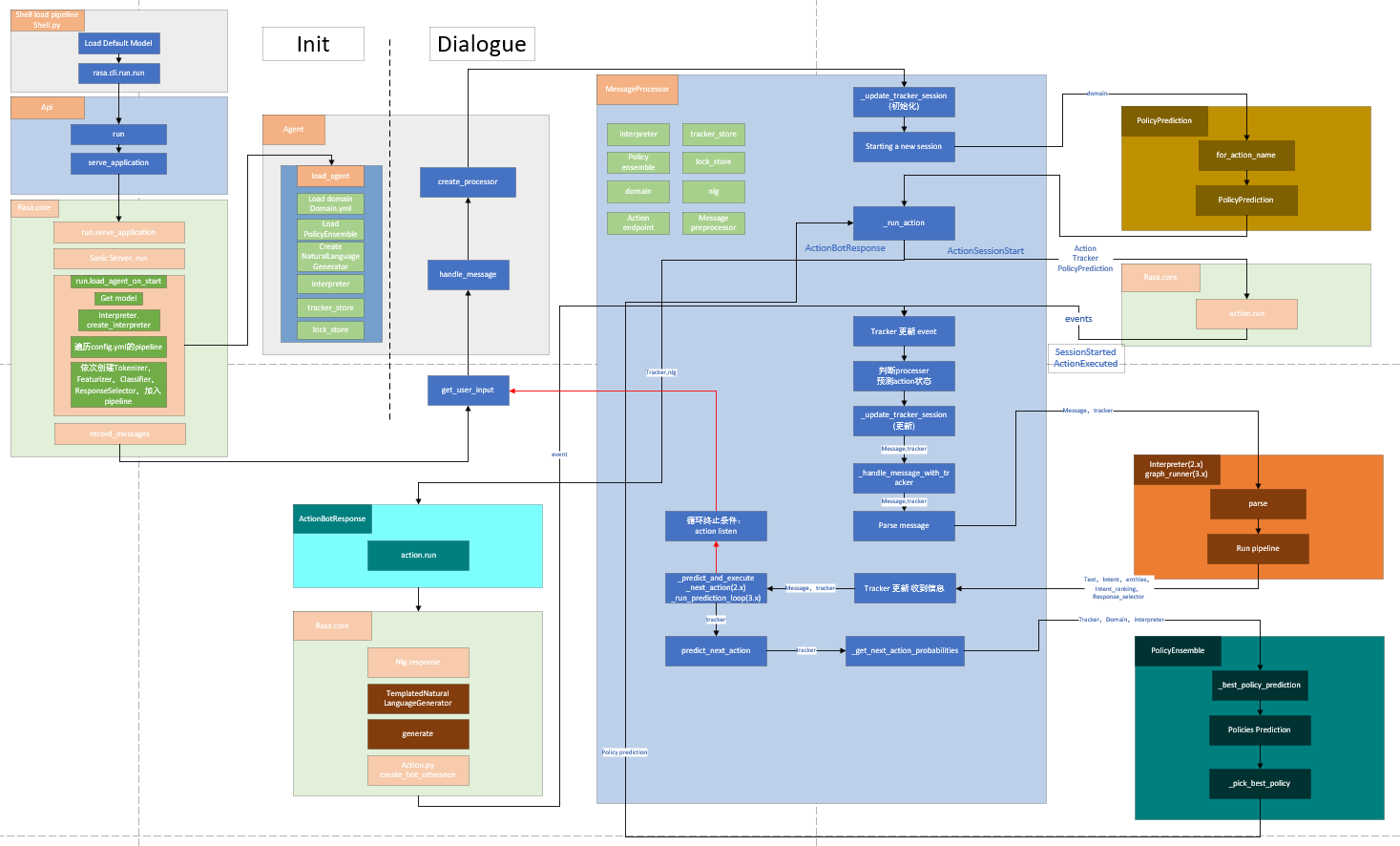
最后,贴几个之前分析2.x数据流画的图,很简单粗暴,没啥道理,如果有兴趣可以去下载了看一下。
3.x版本优化
在这里重点介绍两个功能:
- 动态图功能:Rasa3.x更新了后台计算逻辑,将2.x的机器学习计算pipeline更新为图类型。在之前的版本中,NLU和Core的功能组件一直是各自独立的,虽然在端对端训练中,TEDPolicy也会使用到NLU的特征化模组,但是仍然不够灵活,如下图所示:
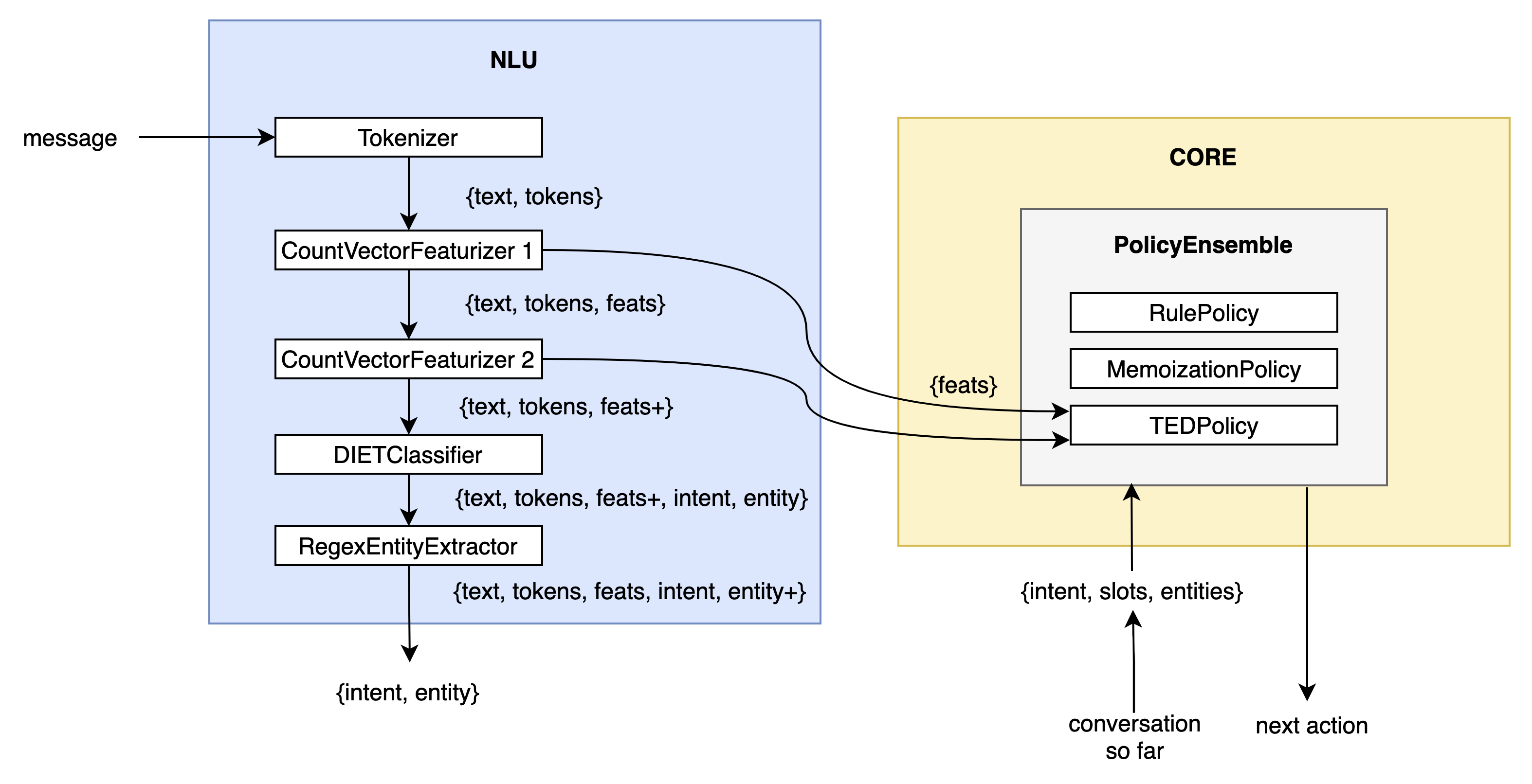 因此在3.x版本中,将以上所有组件拆分,重构为有向无环图:
因此在3.x版本中,将以上所有组件拆分,重构为有向无环图: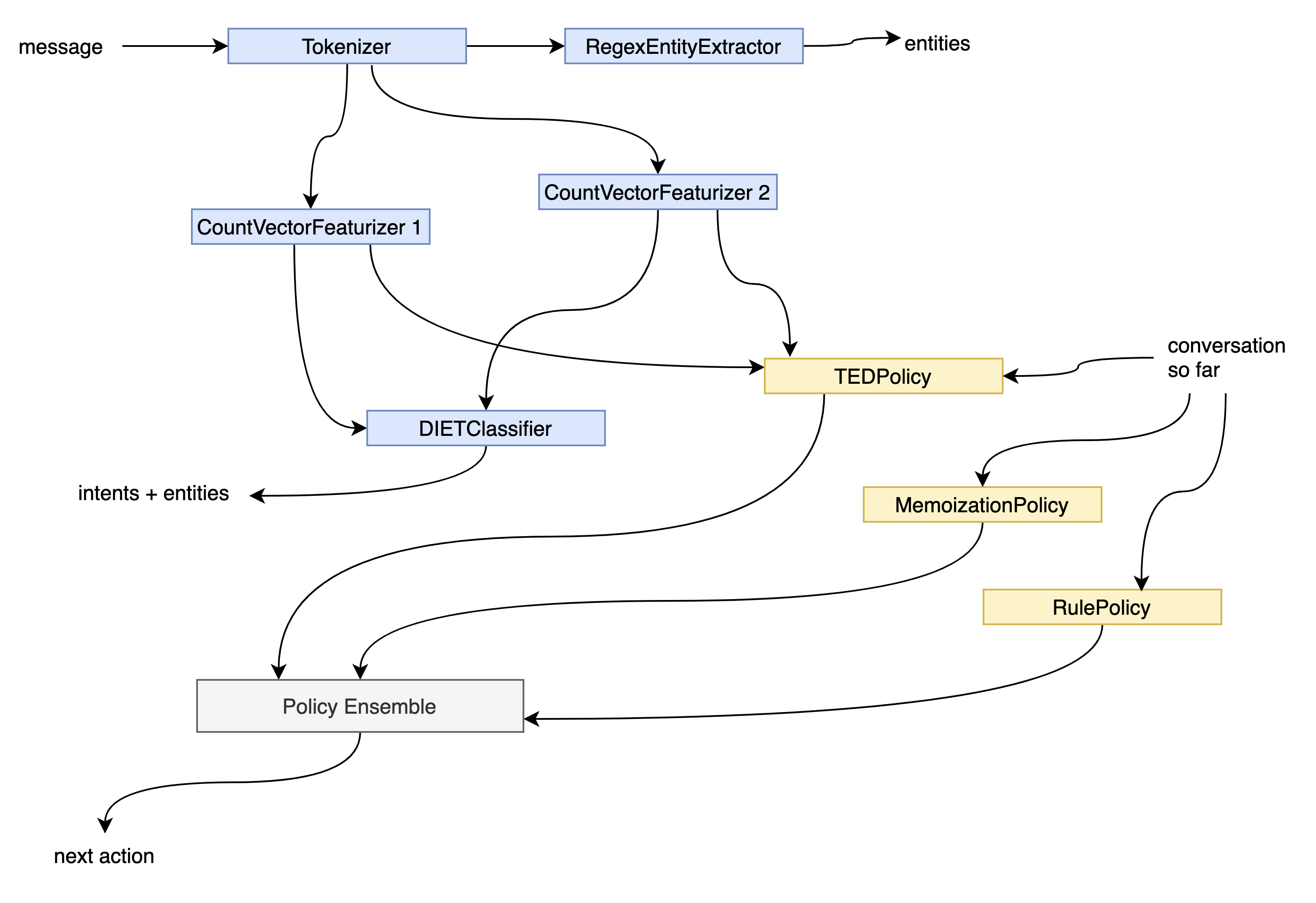 可以看出,图中的每个节点依赖关系都非常明显,DIETClassifier对于Tokenizer并不关注,而RegexEntityExtractor则只关注Tokenizer的信息,从而更加便于并行化和高度定制化。而缓存功能也确保了在一个节点发生变化时,只需要其下游节点重新训练,节约了训练时间。
可以看出,图中的每个节点依赖关系都非常明显,DIETClassifier对于Tokenizer并不关注,而RegexEntityExtractor则只关注Tokenizer的信息,从而更加便于并行化和高度定制化。而缓存功能也确保了在一个节点发生变化时,只需要其下游节点重新训练,节约了训练时间。 - Markers功能:这个功能在3.x版本开发,主要为机器人功能的评估提供服务,通过在对话中标记兴趣点(Marker)触发条件,当满足条件时会触发Marker,以便于提供统计信息,对特定任务进行评估。Markers也是需要通过yml构造的,支持使用and/or/not等操作符来协助判断条件的触发类型。
实践发现的问题
Rasa是一个很完善的架构,但是并不意味着没有问题,在实际操作中,发现了以下几个不足:
- 慢!过多的流程转移,导致一通对话响应时间较长,若加入语音的ASR和TTS,时延就不可想象了;
- 过多历史对话信息的存储严重拖慢了Policy推理的效率,这个应该可以通过设置存储对话轮次数来解决;
- 中文支持较欠缺;
- 过于臃肿。
若用于简单的客服场景还是比较推荐的,但是场景一旦复杂,涉及到语音转文本等内容,就比较不推荐了。当然,也不排除我学习的不够深入,还需要继续研究。
总结
到此,Rasa的理论相关部分结束,下一部分将会进入实践阶段,以一个中文对话机器人案例,将所有的内容串接起来。