Rasa是一个经典的基于Python开发的开源对话机器人框架,经过多年完善,到目前已经发展到了3.x版本,其完备的框架可以确保只需少量训练数据,即可满足大部分客服机器人的需求。由于Rasa发展的实在迅速,本文撰写时,Rasa的版本为3.2.1,但是之前研究的主要是Rasa 2.8.x的结构,读者接触到的更高版本可能新增的特征本文不会涉及,在此表示歉意。
Rasa基本结构
Rasa2和3的基本架构很类似,均为下图所示的结构:
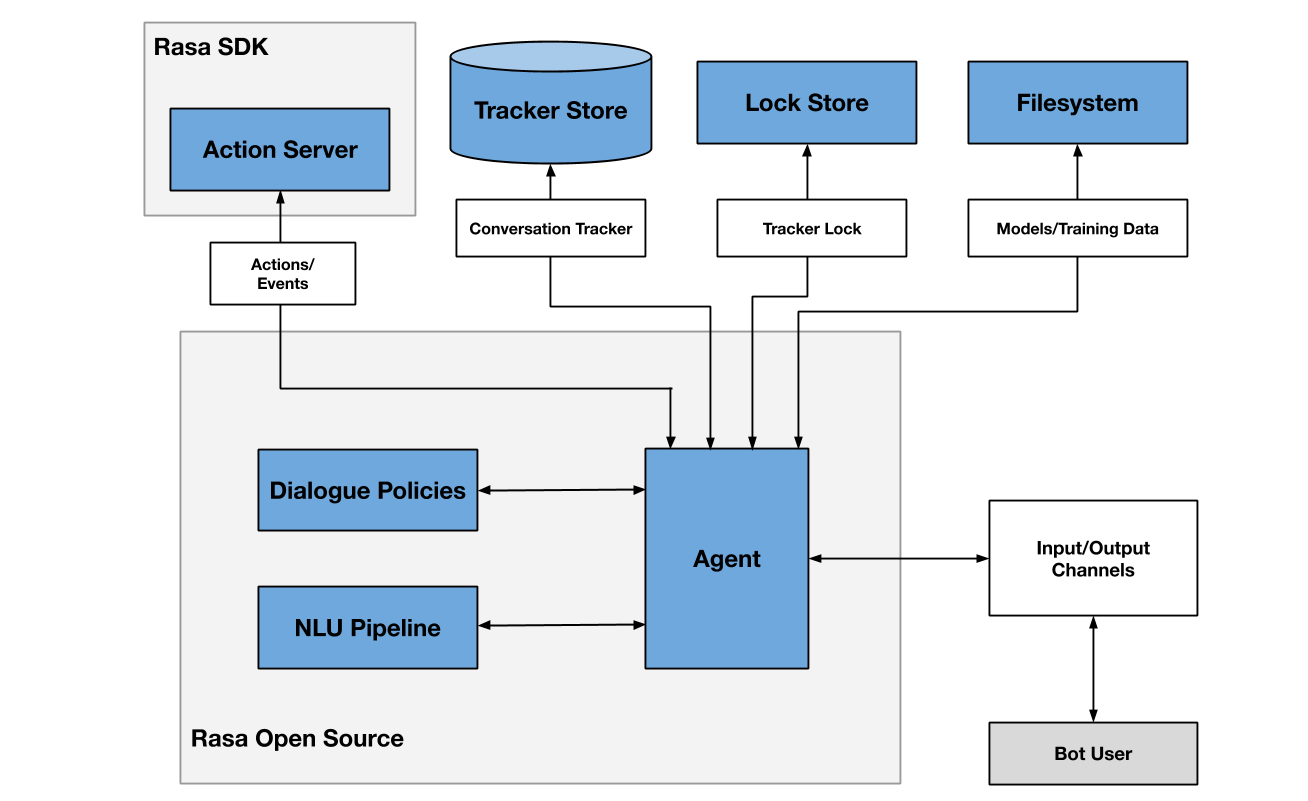
可以看出,Rasa开源系统中主要包含这么几个部分:NLU、对话策略和Agent,而在源码中,对话策略和Agent被包含在了core模块中,而nlu则独自为一模块,两个模块分别可独立提供对话策略管理(core模块)和自然语言理解(NLU模块)功能,在后文我们将会对这两个部分做更详细的解读。
除开上面的核心模块,在图中还可以看到有下面几个模块:
- Action Server:提供可扩展的Action及其对应能力给机器人调用;
- Tracker Store:在Rasa中,每一通对话都会被记录为一个tracker,顾名思义,这里就是存储tracker的地方,有内存存储(默认)、SQL存储、MongoDB存储、Redis存储、DynamoDB 存储以及自定义位置存储;
- Lock Store:为了确保对话的顺序进行,Rasa采用锁方式来锁定消息活动对话,而这些锁的信息也会被存在内存、Redis,或是自定义的位置;
- Filesystem(Model Storage):为训练好的模型提供存储,可以存储在本地硬盘、服务器,甚至各类云服务器(Azure,Google等)上面。
Rasa训练文件结构
介绍了基本架构,下面来看一下Rasa的训练bot文件组成部分,一个完整的bot例子如下结构所示:
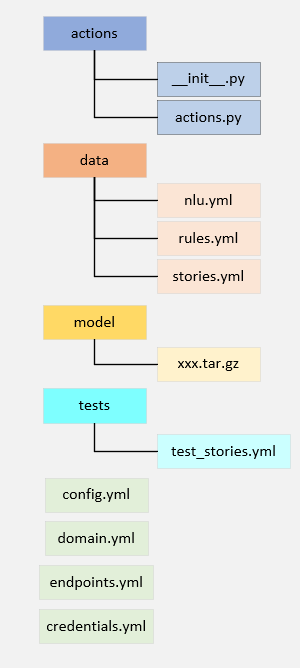
其中各个部分的功能为:
- actions文件夹存放的是自定义的action及其对应的能力实现方式;
- data文件夹包含三个文件:
- nlu.yml:这个文件主要定义了机器人要识别的用户意图,以及对应意图的可能表述,如:意图“问好”,可能表述有你好、早上好、晚上好等等;此外,还可以在这里标注所需要识别的实体,添加同义词,添加识别意图和实体的正则表达式,添加实体速查表等功能;
- rules.yml:这个文件主要为识别到的意图提供强约束的机器人反馈,主要应用于短对话,并且只能根据已有的各种意图做出反应;
- stories.yml:这个文件主要存放训练机器人策略跳转的数据,可以为机器人提供未知对话情况下的反应能力;
- model文件夹主要存储训练好的模型;
- tests文件夹主要存储测试用例test_stories.yml;
- config.yml:为Rasa模型提供整体配置,包括使用语言、NLU处理流水线、对话策略等内容;
- domain.yml:这个文件定义了所有的意图、实体、槽位、机器人回复、需要填充的表单、自定义的action和机器人部分配置;
- endpoints.yml:这个文件可以配置机器人需要的第三方自定义功能,如nlg服务器的url等;
- credentials.yml:这个文件可以配置机器人要调用的第三方平台认证相关功能(没有使用过…)。
Rasa信息处理流程
最后,我们来看一下Rasa对于消息的处理情况,当一条消息进入到Rasa机器人接口后,有下面的一个简单处理流程:
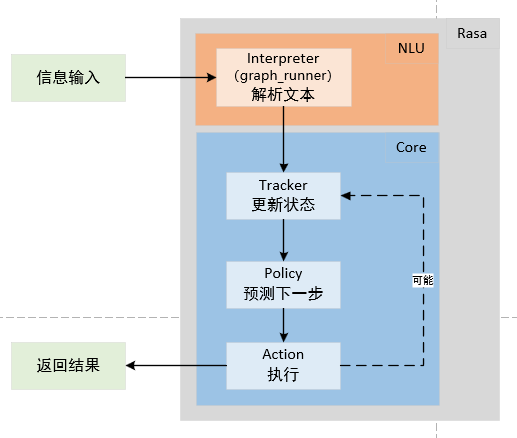
首先,由NLU的Interpreter模块(Rasa2.x)/graph_runner(Rasa3.x)对输入文本进行处理,得到文本的一系列特征,如实体,意图等等;
接下来,将识别到的一系列特征传入本轮对话的的Tracker,它会记录本轮对话的所有对话状态信息;
记录完毕之后,Policy模块将会对Tracker的信息进行处理,并预测出要执行的Action;
最后,执行Action,输出结果,更新Tracker。至此,一个粗略的Rasa信息处理流程结束。
在接下来的部分里面,我们将会依次分析Rasa各模块的细节及使用到的模型和算法,最后,将会以一个中文对话机器人项目来结束这次的学习。